What results are calculated? Where in event time are results calculated? When in processing time are results materialized? How do refinements of results related? If you care about both correctness and the context within which events actually occurred, you must analyze data relative to their inherent event times. We’re going to look closely at three more concepts:
- Triggers: A mechanism for declaring when the output for a window should be materialized relative to some external signal
- Watermarks: A notion of input completeness with respect to event times.
- Accumulation: An accumulation mode specific the relationship between multiple results that are observed for the same window.
Batch Foundations: What and Where
What: Transformations
There are two basic things in Beam:
- PCollections: data set
- PTransforms: Action. Action applies on data set will create a data set
Where: Windowing
Go Streaming: When and how
When is trigger
Triggers provide the answer, when in processing time are results materialized. There are two generally used triggers:
- Repeated update trigger: These periodically generate updated panes for a window as its contents evolve (materialize current state but update the data later)
- Completeness trigger: These materialize a pane for a window only after the input for that window is believed to be complete to some threshold.
Repeated update trigger is mostly used one. Repeated update can provide eventually consistence. Completeness trigger is less frequently encountered. They provide the reason behind data missing and data late.
There are two different approaches to processing-time delays in triggers: aligned delays (where the delay slices up processing time into fixed regions that align across keys and windows) and unaligned delays (where the delay is relative to the data observed within a given window).
Aligned delay trigger is effectively what you get from a microbatch streaming system like Spark Streaming. The nice thing about it is predictability (like every two minutes to update all data); you get regular updates across all modified windows at the same time. That’s also the downside: all updates happen at once, which results in bursty workloads that often require greater peak provisioning to properly handle the load.
It’s easy to see how the unaligned delays spread (first time the system sees the data, then start a time like two minutes. All data in this two minute will be updated in current mini batch) the load out more evenly across time. The actual latencies involved for any given window differ between the two, sometimes more and sometimes less, but in the end the average latency will remain essentially the same.
When: Watermark
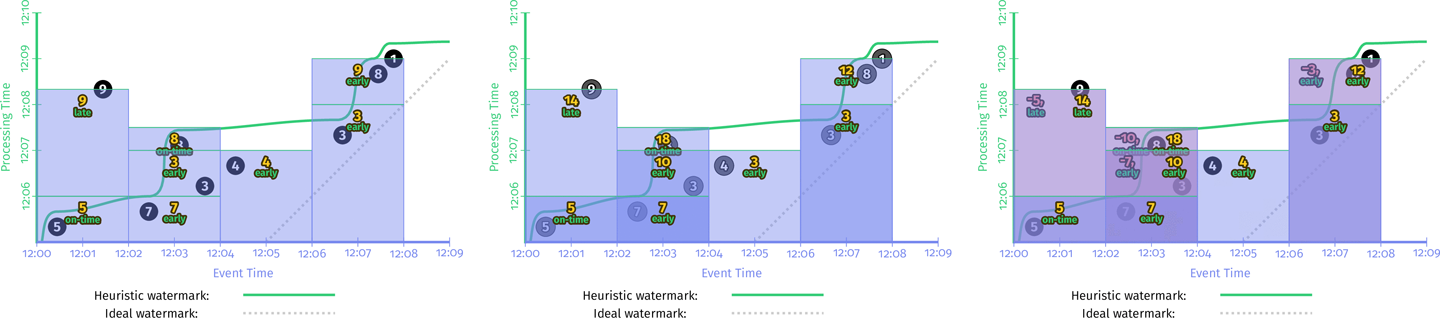
Watermarks are temporal notions of input completeness in the event-time domain. There are two types of watermarks too:
- Perfect watermark: We have perfect knowledge about input data, then we can use perfect watermark.
- Heuristic watermark: Heuristic watermarks use whatever information is available about the inputs (partitions, ordering within partitions if any, growth rates of files, etc.) to provide an estimate of progress that is as accurate as possible.
Watermarks form the foundation of completeness trigger. Perfect watermark may be bad for production too. Some random long tail delay data will hang whole pipeline, even if you can have perfect watermarks.
A great example of a missing-data use case is outer joins. Without a notion of completeness like watermarks, how do you know when to give up and emit a partial join rather than continue to wait for that join to complete? Event-time watermarks are important for real world, but it is hard to get event-time watermarks.
Two short comes of watermarks:
- Too slow. Some random delay in event-time will hold how pipeline until the missing data recover (like 12:01 data is delay and 12:02-12:04 data arrived. System will hold until missing data is coming)
- Too fast. Wrong watermark will omit some data
You simply cannot get correctness and low latency solely on the notion of completeness.
When: Early/On-time/Late Triggers FTW
Combine repeated update trigger and completeness trigger will help.
• Zero or more early panes, which are the result of a repeated update trigger that periodically fires up until the watermark passes the end of the window. The panes generated by these firings contain speculative results but allow us to observe the evolution of the window over time as new input data arrive. This compensates for the shortcoming of watermarks sometimes being too slow.
• At most one on-time pane, which is the result of the completeness/watermark trigger firing after the watermark passes the end of the window. This firing is special because it provides an assertion that the system now believes the input for this window to be complete.7 This means that it is now safe to reason about missing data; for example, to emit a partial join when performing an outer join.
• Zero or more late panes, which are the result of another (possibly different) repeated update trigger that periodically fires any time late data arrive after the watermark has passed the end of the window. In the case of a perfect watermark, there will always be zero late panes. But in the case of a heuristic watermark, any data the watermark failed to properly account for will result in a late firing. This compensates for the shortcoming of watermarks being too fast.
But in real world, you still don’t have any good way of knowing just how long the state should be kept. That’s where allowed lateness comes in.

When: Allowed Lateness (i.e., Garbage Collection)
We will eventually run out of disk space to keep every state for infinite unbound stream. A clean and concise way of doing this is by defining a horizon on the allowed lateness within the system.
Using processing time would leave the garbage collection policy vulnerable to issues within the pipeline itself (e.g., workers crashing, causing the pipeline to stall for a few minutes), which could lead to windows that didn’t actually have a chance to handle late data that they otherwise should have. Specify the horizon on event time domain (have low and high difference. Low means the oldest unprocessed record, high means the newest record the system is aware of), garbage collection is directly tied to actually progress of pipeline which decrease the possibility that window will miss data.
How: Accumulation
How do refinements of results relate? There are three different modes of accumulation:
- Discard: Every time a pane is materialized, any stored state is discarded. (if downstream have accumulation mode, this is useful.)
- Accumulation: Every time a pane is materialized, any stored state is retained, and future inputs are accumulated into existing state. Accumulating mode is useful when later results can simply overwrite previous results, such as when storing output in a key/value store like HBase
- Accumulating and retracting: When producing a new pane, it also produces independent retractions for the previous pane(s). Told downstream which window is updated and both new and old value of this window.
Mention: If current state is discarded mode, but downstream is accumulation mode, then downstream will get right answer.
Recap
- What results are calculated? = transformations.
- Where in event time are results calculated? = windowing.
- When in processing time are results materialized? = triggers plus watermarks.
- How do refinements of results relate? = accumulation.